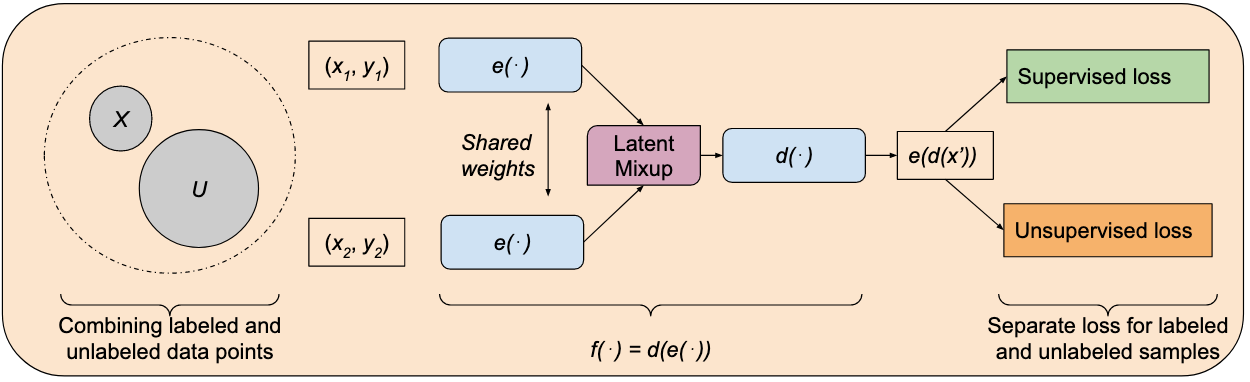
How to address the data hunger of deep learning? 1) how to utilize the unlabeled data in the context of deep learning? 2) how to augment data. In semi supervised learning, we leverage the idea of the smoothness of classifier with respect to input or with respect to latent representation to regularize the training. Employing ideas from analytical learning theory and function continuity, we show that enforcing the notion of smoothness during training by utlizing unlabeled data improves accuracy.
In data augmentation, we try to learn transformations from data itself to apply on other data.
I am working with Prashnna Kumar Gyawali in semi supervised learning and with Nilesh Kumar in data augmentation under superviion of Prof. Linwei Wang.
References
-
Gyawali, P.K., Ghimire, S. and Wang, L., 2020. Enhancing Mixup-based Semi-Supervised Learning with Explicit Lipschitz Regularization. arXiv preprint arXiv:2009.11416.
-
Gyawali, P.K., Ghimire, S., Bajracharya, P., Li, Z. and Wang, L., 2020. Semi-supervised Medical Image Classification with Global Latent Mixing. arXiv preprint arXiv:2005.11217.
-
Gyawali, P.K., Li, Z., Ghimire, S. and Wang, L., 2019, October. Semi-supervised learning by disentangling and self-ensembling over stochastic latent space. In International Conference on Medical Image Computing and Computer-Assisted Intervention (pp. 766-774). Springer, Cham.